Some notes on CSV spelunking
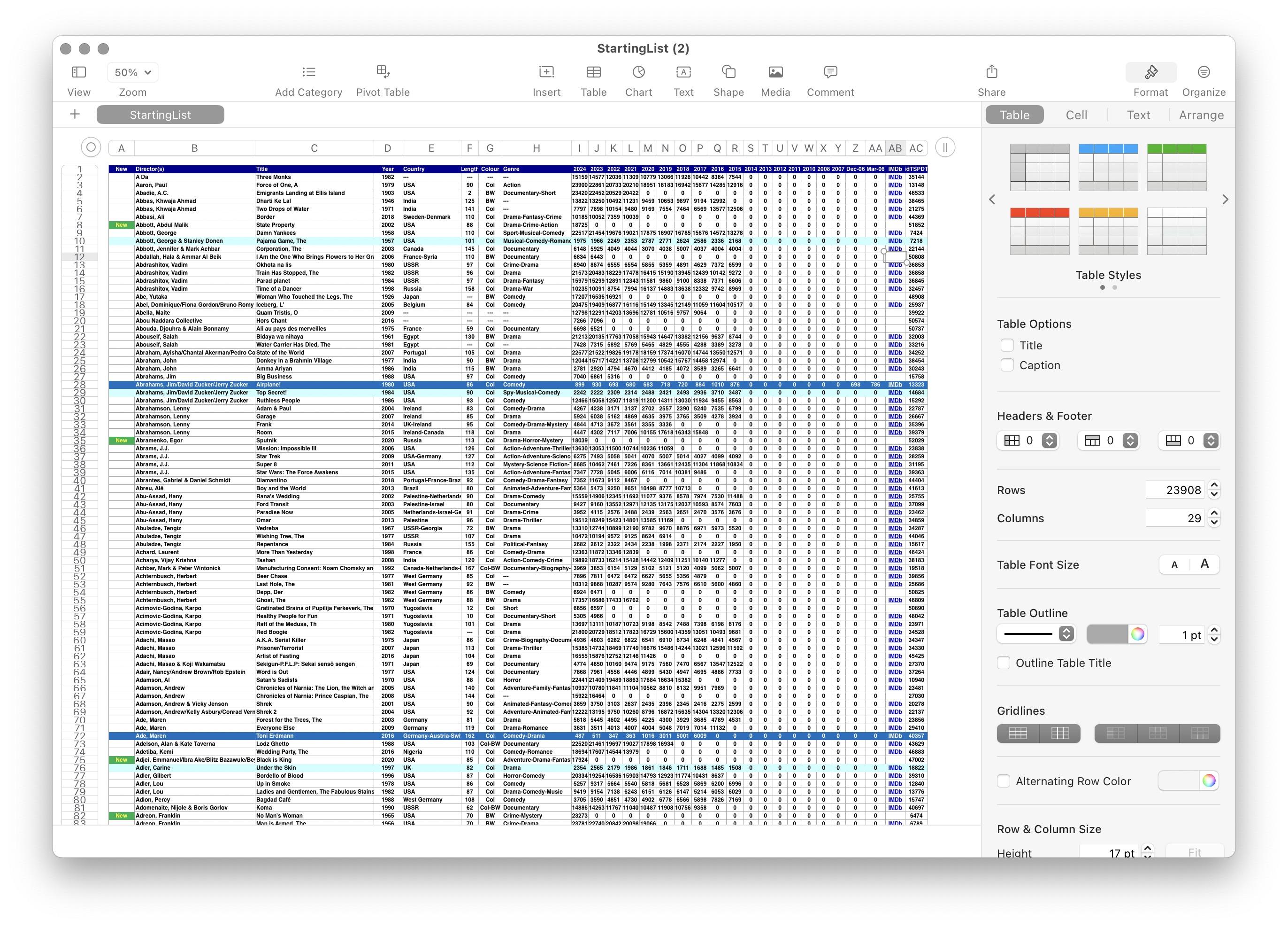
Recently I made a web app to explore the They Shoot Pictures Don’t They list of greatest films of all time. TSPDT fortunately provides a massive spreadsheet export of their starting list of ~24,000 films. However, the data is a bit chaotic - you get an XLS file of all the films with title, director, year, country, length, color, genre, the ranking of the movie over time, an IMDB link, and a tspdt id (a universal identifier for future versions of TSPDT). I had previously attempted this with previous years, which did not include an IMDB link --- matching movies by title and year is doable, but not as accurate as if we get a canonical ID.
Luckily, the IMDB link is huge — via the IMDB ID we can look the movie up in The Movie Database (TMDB), which is a beacon of open, free APIs that one can build on (Letterboxd uses them, among many other apps). We can get photos, credits, descriptions, keywords, and more. Just need to use the Find by Id endpoint.
In order to get our XLS file in a workable format, we have a few choices. The most direct way would be to use any spreadsheet app to convert it to CSV. Once it’s in CSV, we can use D3’s csvParse method to get it into a JavaScript object we can manipulate. Not too bad!
But we’re left with one big problem: the IMDB Link is provided as a rich link, not just the URL. Oh, no! Why! When we export that to CSV, by default Numbers.app will just list that cell’s value as “IMDb”. Not helpful!
My Excel Fu is terrible, and I don’t have a copy of Excel, so I fired up Google Sheets. Unbelievably, Google Sheets does not give you an easy way to do this. The best answers they gave you were to press command c and command v - obviously undesirable for 24,000 links! Google Sheets provides “App Scripts” which lets me write JavaScript to extract a link. However, this didn’t work for a massive list of 24,000 films --- the tab just froze for me.
Turns out there’s two different kinds of hyperlinks in Google Sheets: rich hyperlinks, with no formula, and hyperlinks which are made with a formula. Written as a formula, hyperlinks can be extracted. But as a rich link, I had to turn to the weird world of Google Sheets apps. I found one that promised to extract URLs, gave it write access to all my spreadsheets (lol), and ran it. It worked for one cell, but once again gave errors when I ran it for the entire spreadsheet.

Sometimes, when chasing rabbit holes like this, it’s better to just do things the “unoptimal” way and move on rather than spend hours trying to find the perfect way. So I ended up selecting 1,000 rows at a time and just doing this 24 times to get the rich links transformed to a formula HYPERLINK(URL, DISPLAY) of sorts. Then I could write a regex to match the ID. Luckily this was trivial since the URLs were all formatted in the same way (with a trailing slash), so I could actually just call FORMULATEXT and do something like REGEXEXTRACT(FORMULATEXT(AB3), "title/(.*?)/").
With a quick download to CSV, finally… we have a CSV with the IMDB IDs.
Transforming CSV into Javascript Objects and Relational SQL
Once we have data in CSV form, it becomes a lot easier to parse and do things with.
D3 conveniently provides csvParse, which works great --- you give it some CSV as a string, and it turns it into an array of JavaScript Objects. It’s typescript-friendly, as well, taking a generic of the column headers. So we can do something like this:
type MovieData = {
"2007": string;
"2008": string;
"2010": string;
"2011": string;
"2012": string;
"2013": string;
"2014": string;
"2015": string;
"2016": string;
"2017": string;
"2018": string;
"2019": string;
"2020": string;
"2021": string;
"2022": string;
"2023": string;
"2024": string;
New: string;
"Director(s)": string;
Title: string;
Year: string;
Country: string;
Length: string;
Colour: string;
Genre: string;
"Dec-06": string;
"Mar-06": string;
IMDb: string;
IMDB_ID: string;
idTSPDT: string;
};
type MovieColumn = keyof MovieData;
const parsed = csvParse<MovieColumn>(text);(Btw, I generated that intial type by just copying the columns and asking Copilot to turn it into a type.)
Once we have everything parsed, we can loop through, query the TMDB API, and grab the movie. I saved all this into a SQLite database, extracted text embeddings from the overview and saved it into a vector database, but that’s beyond the scope of this post.
For more, you can view the codebase, the specific CSV parsing file, or look at the finished project.